Data-driven businesses are hard to build. In fact, any sort of data program is hard to launch in an organization. The first step is often understanding the “business-side” of the data and deciding on one or two use cases that make good pilots or proofs-of-concept. These pilot projects can be critical in demonstrating the current data capabilities of an organization and the possible value of data for driving business outcomes. An unexpected benefit of a data pilot is what the project can reveal about the organization’s data quality.
How Simatree Uses Report Automation Pilot Projects to Improve Data Quality
One simple, but powerful initial pilot project is automating a manual report. With manual reporting, for example, there will almost certainly be data quality issues to identify and remediate due to human error or staff-developed workarounds. Often small errors on a single data entry can compound over a dataset or multiple datasets for a complete report (see visual below). Although remediating data quality issues organization-wide can seem like a daunting task, teams can avoid the headache by cleaning up one dataset to apply data quality improvements across the organization.
When automating a manual report, a team can check data quality by comparing small subsets of the automatically generated and manually generated reports to:
- Verify that the data is accurate OR
- If errors are found, fix them and apply the fixes across the dataset
To identify data quality issues, a pilot team should create exception reports that identify and list common types of issues to fix, such as duplicates, missing records, and null values. Exception reports represent a ‘Quick Fix’ solution that may also surface needed process changes to stop recurrences, which calls for preventative solutions (see below for details).
To track progress against identified data quality issues, teams managing data should create trend reports for their leadership team. These reports should track trends (e.g., trending up, trending down) for each type of data quality issue identified, as well as overall progress. Further, remediation plans should be time bound with clear goals.
How to Roll Out Organization-Wide
Once one dataset is in good shape, the pilot team can apply the learnings to other datasets and reports within their team. After the pilot team demonstrates success, and with organization-wide collaboration, the learnings can be applied throughout the organization. For example, good, clean data used for a finance team’s reporting can also be applied to an operations team’s reporting, and so on. Further, quality data can then be applied to other business initiatives beyond reporting.
Having clean and consistent data across teams requires centralized data assets. Centralizing data access enables better cross-silo collaboration, helps eliminate rework, and ensures shared knowledge of definitions and data quality concerns across teams. It also raises the standard for data quality and management across the entire organization. While data centralization may raise security concerns, there are simple ways to control who sees what – as micro as cell-level security features in a dataset – such that the organization can have these benefits of centralization without the risks.
10 Common Data Quality Issues Identified Through the Pilot Approach
Through pilot projects such as this, Simatree has identified 10 common data quality issues and solutions, below. While exception reports can identify data quality issues after the fact, the below solutions can prevent data quality challenges before they begin. The types of data quality challenges exception reports identify can help organizations prioritize which preventative solutions to implement first.
10 Common Data Quality Issues Identified Through the Pilot Approach
| ISSUE | DESCRIPTION | IMPACT | PREVENTATIVE SOLUTION |
|---|---|---|---|
| Duplicates | The same value used multiple times across records in fields (i.e., columns) that should have unique identifiers | Results in double counting data, making it inaccurate and, therefore, providing unreliable insights | Create an alert on a unique identifier field so that, if the value already exists in the system, the record cannot be saved until that is fixed |
| Missing Records | Record(s) found in one data source are unexpectedly not found in another data source | Results in undercounting, insufficient and/or incomplete data for product accounting, and therefore unreliable insights | Create business rules to ensure that when a record gets entered into one system, it triggers a chain of events to record it in every relevant system |
| Null Values | Critical fields are blank | Similar to missing records, nulls can skew data for impacted fields and result in unreliable insights | Lock down fields where null values shouldn’t be allowed so that records cannot be saved if the fields are not filled out |
| Inconsistent Rules Around Field Use | Lack of clear business rules and/or consistent practice leads to individuals using multiple fields in a data source for the same type of data | Will lead to inaccurate counting and potentially skew key metrics calculated from data impacted by inconsistencies – client metrics in this instance | Create clear business rules for how to enter data into a source system; audit systems regularly to proactively identify misuse of fields |
| Timing Issues | Depending upon when a report is run, the underlying data may be incomplete | Incomplete daily sales data produces unreliable insights | Analyze the data flows and work with business leaders to set business rules for when data should be pulled in and when a day’s value should be considered final |
| Siloed Definitions | Different groups within the organization may view/calculate data differently | Results in multiple views of the truth around the organization, potentially paralyzing decision-making | Clearly define and align on key metrics across teams/groups, and create a centralized repository of clearly defined metrics. Explore the development of automated dashboards and reports that lock users into consistent metrics |
| Incomplete Reference Tables | When a field in a dataset pulls in data from an external table, record(s) in the field will show up as unknown in the dataset if the associated record is not contained in the external table | Results in incomplete product data and can skew the data similarly as with null values; it therefore provides unreliable insights | Create a robust data architecture and work with business leaders to ensure that the reference tables are complete and well defined |
| Free Text Fields | Free text fields allow users to manually input misspelled or incorrect values | Makes it difficult to perform reliable analysis with all the misplaced and inaccurate data. Unless someone manually cleans up the free text fields, there may be typos in any report you produce | Lock down fields that should only have a few acceptable entries; make it a drop-down list instead of free text |
| Integration Errors | When acquiring new businesses/clients and loading their data into existing systems, issues and errors may occur if their data is structured differently or of lower quality than the data in existing systems | Results in poorer data quality (insufficient, incomplete, and hard to interpret data), and therefore limits ability to realize underwritten or otherwise assumed synergies | Conduct a gap analysis to understand data quality gaps with newly acquired entity prior to integration. Determine whether to integrate systems or to maintain parallel systems. Set clear business rules for what to do if an acquired company/client’s data is not up to the business’ data quality standard. Rules should cover data cleansing standards and procedures, acceptable alternative data sources for gap-filling, approval process, etc. |
| Technology Incompatibility | Depending on the system used for data extraction, the data pipeline used may not have the rights to read in the entire dataset | With data read in incompletely, the dataset becomes unreliable for analysis and insight generation | Be agile with technology usage and verify that all necessary data is received. If a certain extraction method isn’t working, consider exploring other options like an excel report instead of a direct connection |
Small One-Off Data Quality Issues Can Quickly Add Up Across a Dataset
The visual below shows how small errors on individual entries can compound across a dataset to reduce trust in the complete dataset and with the associated reports. Please reference the key below for a description of each data quality issue identified in this dataset.
Initial Dataset

Ingested Data View
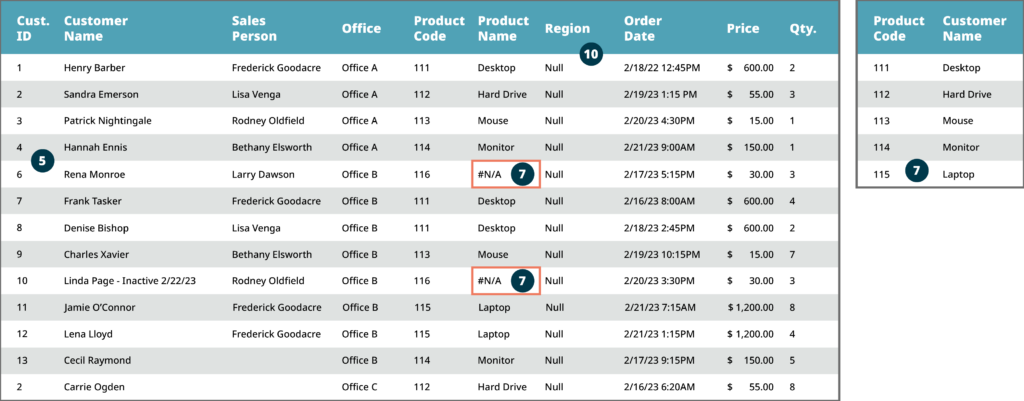
Key

Conclusion
Data analytics pilots have the dual benefit of spurring data quality issue identification and remediation, while also demonstrating the value of analytics to the business. With assurances of data quality and a proven use-case of data analytics in the organization, leaders can be confident in making data-driven decisions going forward. More importantly, a successful data analytics pilot enables leaders to develop and execute on more analytics use cases. In essence, one successful pilot can set an organization on a roadmap to a data-driven future.


